LinkedDataHub 2.0: The New Knowledge Graph Experience
Introducing a completely redesigned release with a unique user experience
March 8, 2021
In this post we are excited to present the new LinkedDataHub 2.0. It is the only data-driven Knowledge Graph platform built with RDF and declarative technologies from the ground up. With this low code infrastructure you can effectively manage data and build apps on graph data.
LinkedDataHub 2.0 features a new intuitive Knowledge Graph user experience: faceted search for easy filtering of results, parallax navigation for jumping across related result sets, and visualizations of query results for accessible presentation.
Knowledge Graphs are at the center of a data-centric enterprise, but this paradigm shift will also disrupt the software architecture. In order to take full advantage of the KG potential, the software has to be designed for it and around it — simply replacing a legacy database with a triplestore achieves nothing. Today we are excited to share the new release of LinkedDataHub 2.0 open-source edition.
LinkedDataHub can be used to manage data and build applications on RDF Knowledge Graphs. LinkedDataHub 2.0 offers multiple new ways to browse, explore and visualize Knowledge Graphs, leading to a better understanding of data through more intuitive navigation. The faceted search and the set-based (parallax) navigation are intuitive UI features that allow drilling down and traversing data with the power of SPARQL, but without having to write queries. Charts and other layout modes render the SPARQL results in a visually appealing way.
LinkedDataHub 2.0 is designed for:
- domain experts who work with RDF data and need an accessible low-code publishing, exploration and management tool
- developers who are looking for a declarative full stack framework for web application and API development
- data engineers who need an open-source RDF platform that can be customized for a variety of use cases
Low-code infrastructure for your Knowledge Graphs
To our knowledge, LinkedDataHub 2.0 is the only data-driven Knowledge Graph platform built with RDF and declarative technologies from the ground up. Its architecture is completely data-driven: applications and documents are defined as data, managed using a single generic HTTP API and presented using declarative technologies. The default application structure and user interface are provided, but they can be completely overridden and customized. Unless a custom server-side processing is required, no imperative code such as Java or JavaScript needs to be involved at all.
The low-code approach to application development lets end-users customize the platform to their needs without having to be a programmer. As an example of this approach, using only SPARQL queries, we have created an enterprise Knowledge Graph of the iconic Northwind Traders database (originally relational) that contains data about a fictitious trading company and its products, customers, orders etc.
Using Northwind Traders as an example, we will introduce you to a new Knowledge Graph experience featuring faceted search and parallax. The demo application can be found here.
Faceted search
A drill-down navigation flow will typically start with filtering a collection (container, in LinkedDataHub-speak) of resources using faceted search. Faceted search is a common UI feature that allows filtering and narrowing down query results by selecting a combination of values from a given set of options for one or more properties. Each option usually indicates the number of results they will produce when selected. Alternatively, faceted search can appear as a text search filter for string values or a value range filter for numerical or temporal values.
We can refine our search for products using the Category and Provider facets (on the left hand side). For example, if we want to see all the products from the meat/poultry category, sold by My Maison for instance, we select the corresponding checkboxes and get a filtered result.
With each facet change, the Total results counter changes to reflect the total number of results with current facet filters applied.
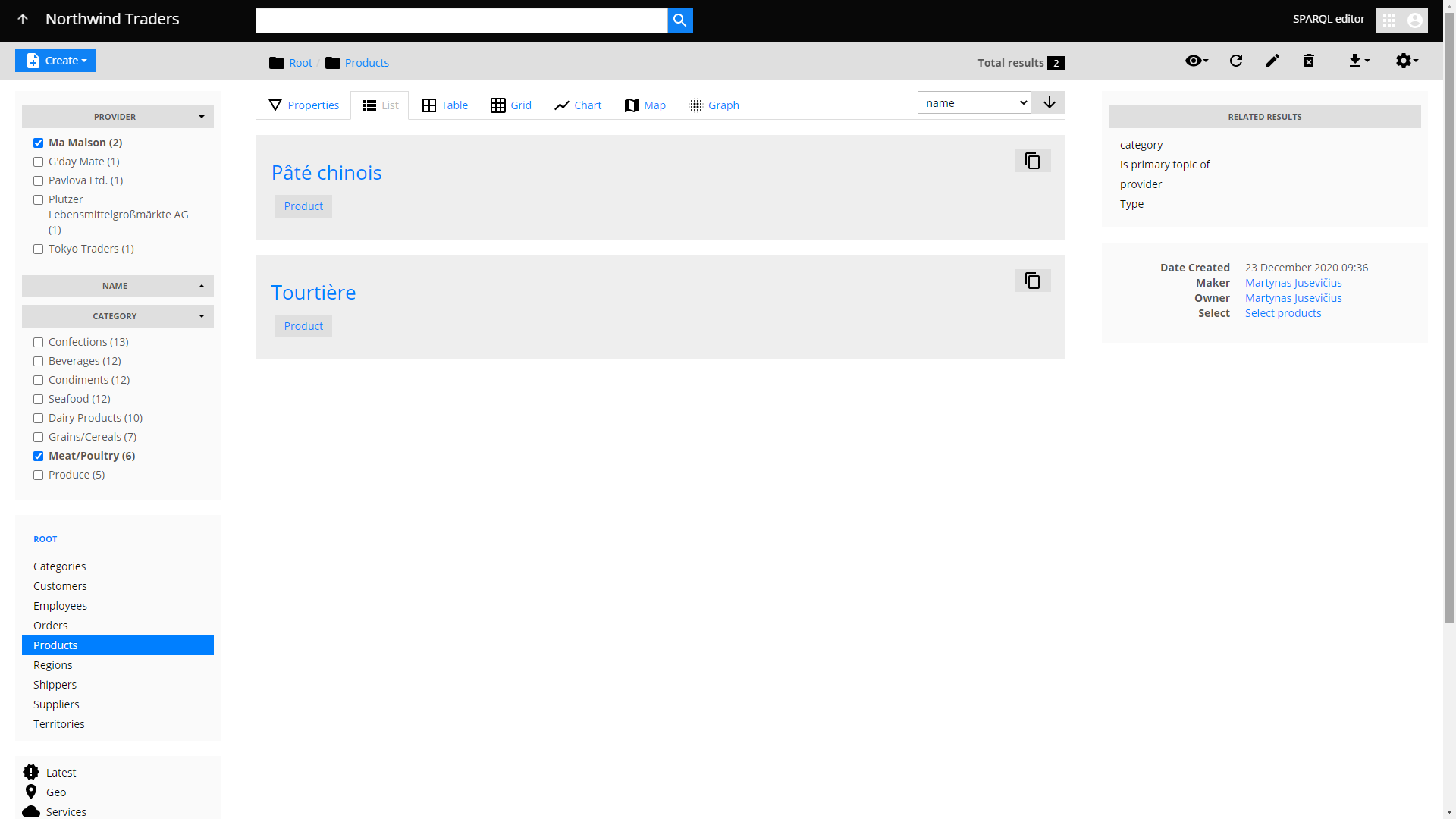
Faceted search
Parallax: set-based navigation
After results are filtered using faceted search, we can apply parallax navigation to find related results. Parallax is a powerful UI feature that allows the user to navigate from a collection (set) of items to a related collection, the relationship being simply an RDF property.
This is rather unique and unusual in the context of the current web, where navigation is possible from collections to items but not to other collections. For example, one can navigate from a collection of products on Amazon to each of those products, where the manufacturer will be indicated, but one cannot navigate to a collection of all manufacturers of those products at once. Imagine compiling such a list by opening each product page and taking note of the manufacturer, versus one click using parallax.
The parallax concept is not widely known but it is not new — it was demonstrated over graph data in Freebase as far back as 2008. Freebase makers Metaweb were acquired by Google soon after and Freebase became the origin of the Google Knowledge Graph.
Parallax can be used as a more intuitive alternative to a visual query builder. It works seamlessly in combination with the faceted search, enabling further exploration of the filtered results.
We have introduced parallax as a new navigation feature in LinkedDataHub 2.0, called Related results in the right-hand side column in the container layout. It appears as a list of properties from the current result set that can be used to "jump" to the next related result set.
Parallax and faceted search in action
Consider Northwind Traders again as our business setting. Let's say due to new Brexit-related restrictions NT needs new certifications for their meat/poultry products. The providers of this product category have to be contacted and inquired about the certifications of their products. How do we quickly find the necessary contacts in the company data?
With parallax (called Related results in the UI) we can get the answer to this question simply by navigating. The question structure translates directly into navigation steps:
- Go to the Products container
- Filter them by choosing Meat/Poultry as the Category in the faceted search
- Navigate to meat/poultry providers by choosing Provider in the Related results
- Navigate to their employees by choosing Employee in the related results
In 3 clicks we got a list of 6 people that need to be contacted, without having to write any queries or code.
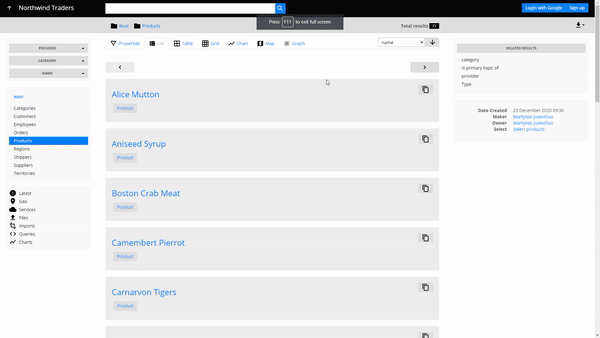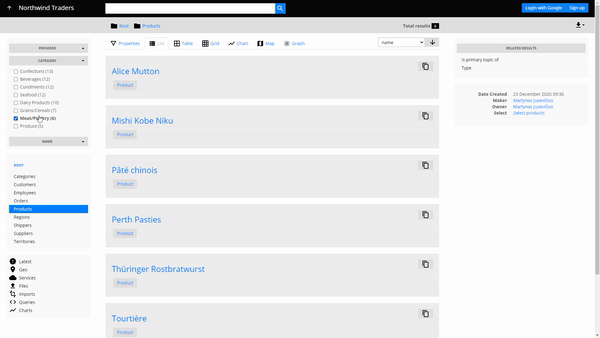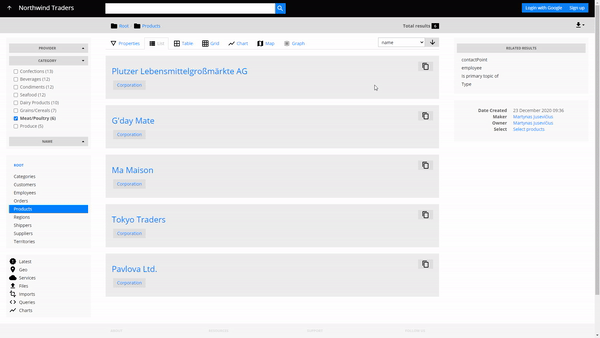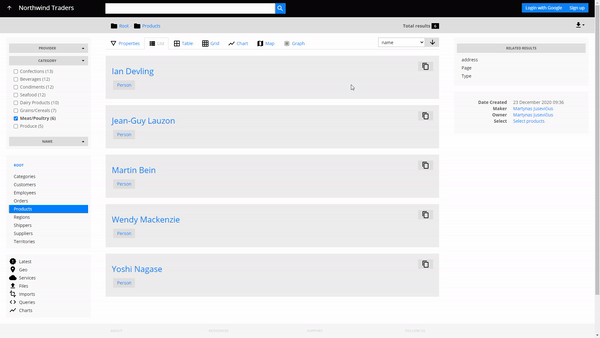
Parallax navigation
Parallax is also useful if you don't have a specific question in mind, but just want to explore the data. For example, if you are new to the team and going through an onboarding process, you can use the parallax navigation to explore the relationships within the company. In the Northwind Traders scenario, using LinkedDataHub 2.0 you can easily see who your colleagues are, what roles do they have, who their managers are, what regions they are responsible for, what products they sell and so on. All in all, you can follow your nose and take whatever path you want, and backtrack to the previous state if necessary.
Parallax helps you discover the data intuitively, get a feel of it and be able to understand what you can expect in the dataset.
Visualizing query results
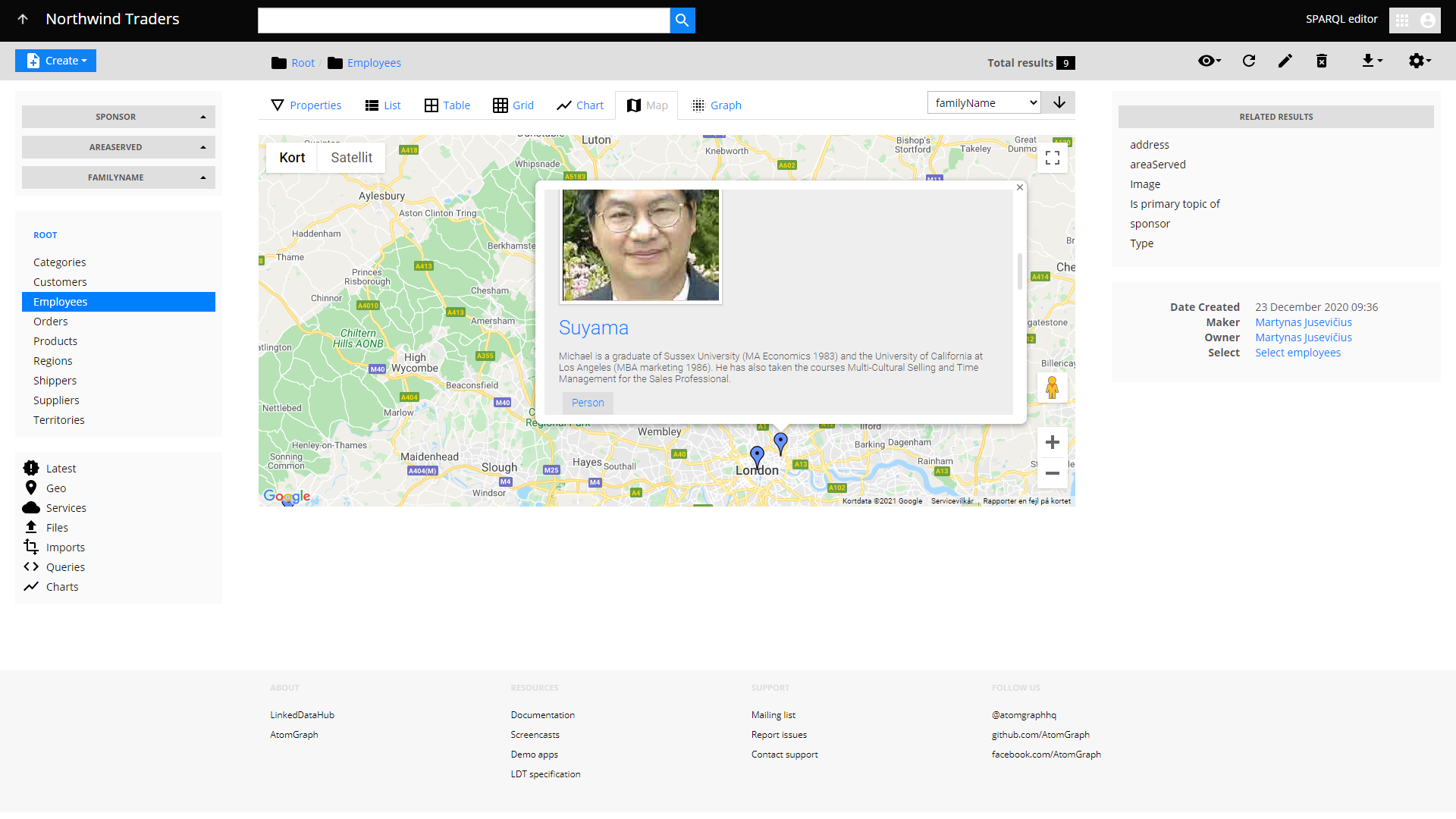
LinkedDataHub 2.0 supports multiple layout modes for SPARQL results. There is a number of available container layout modes:
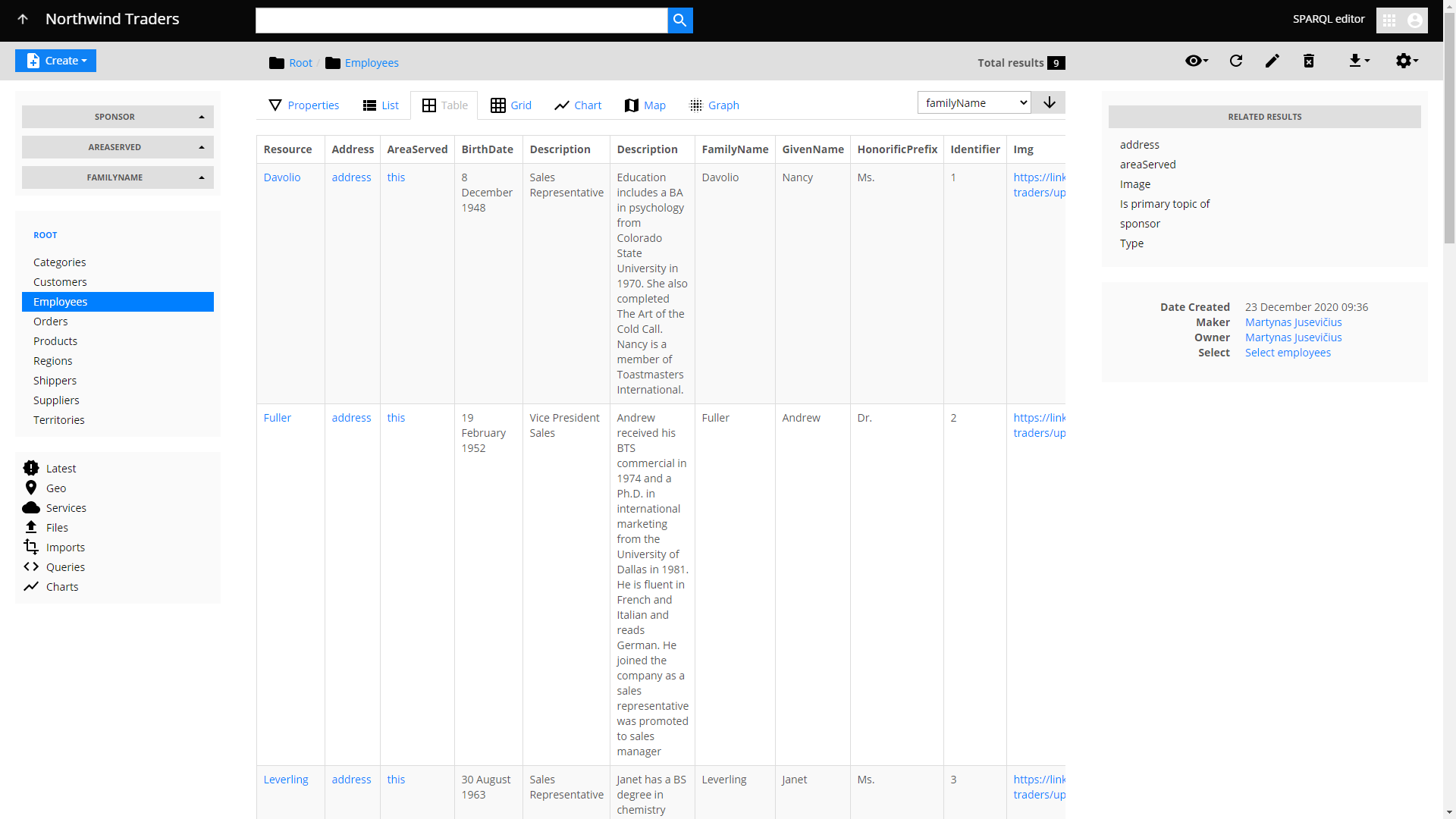
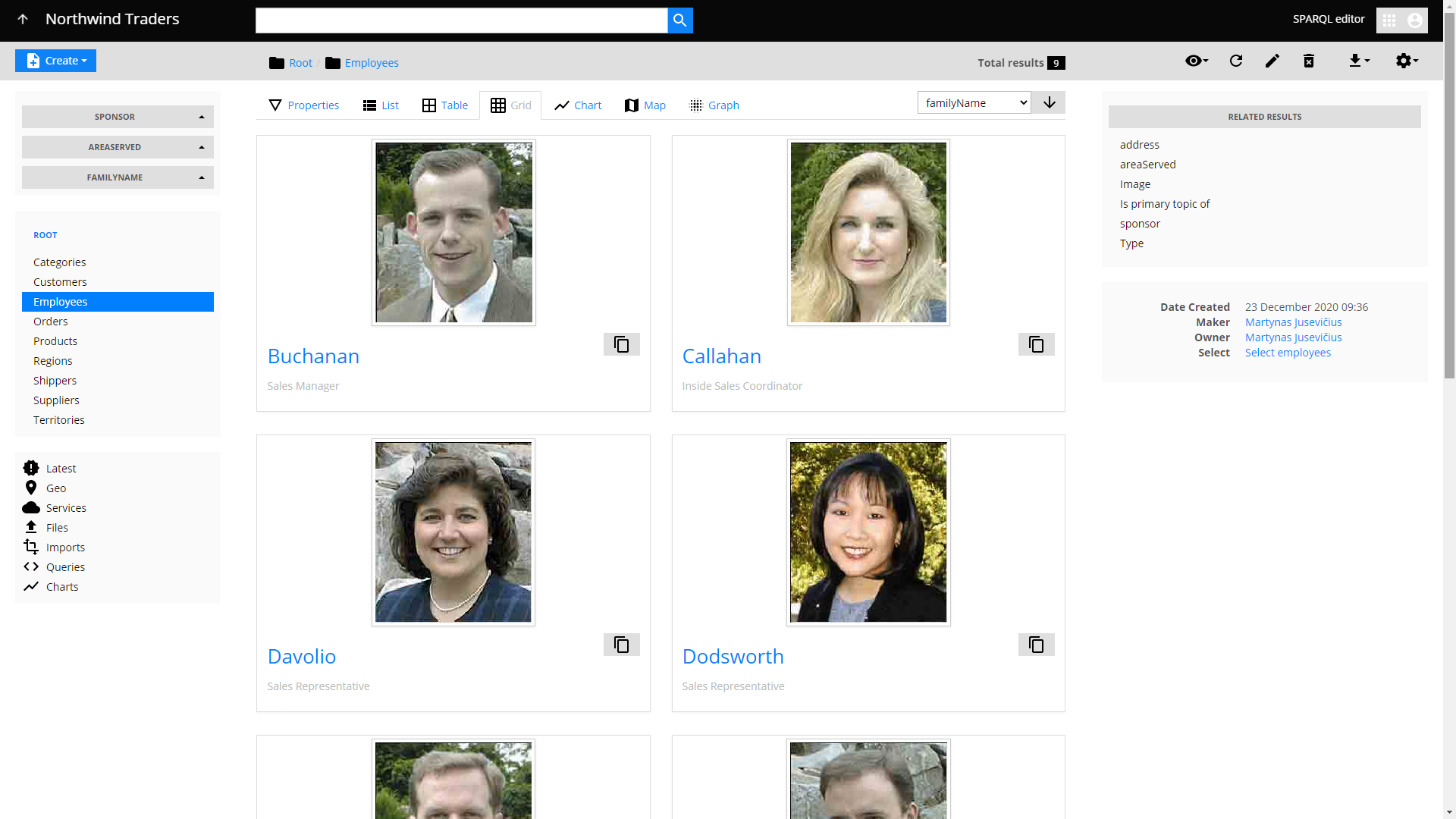
In case you've been wondering what the top-selling product in the Northwind Traders dataset is, we have an answer for you — it's Côte de Blaye, a wine 🍷.
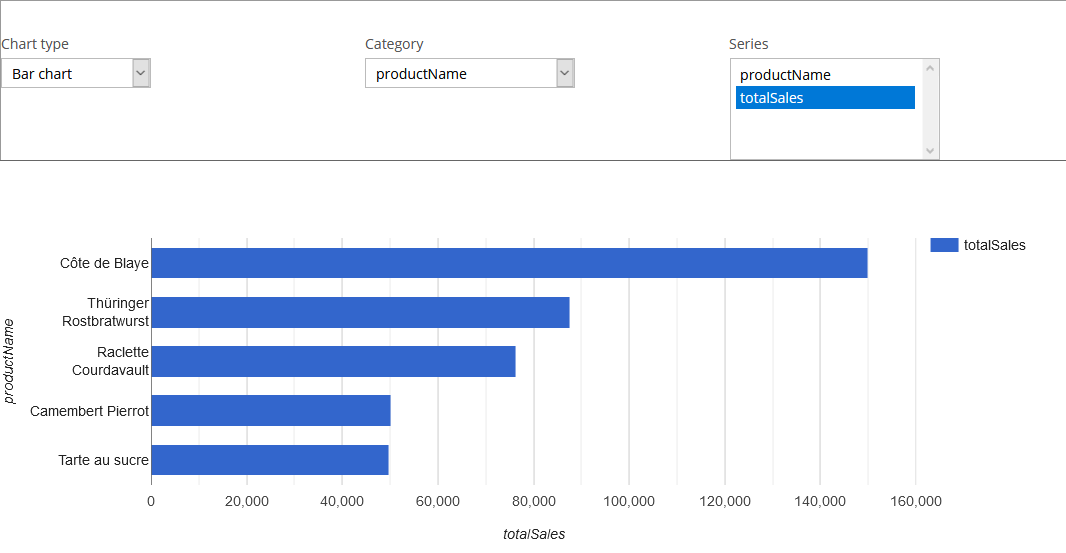
Top-selling Northwind Traders products
LinkedDataHub 2.0: The user-oriented entrypoint to your Knowledge Graph
There are a lot of companies experimenting with Knowledge Graphs and it seems like everyone is trying to build their own software around them. It is like web development 20 years ago, when developers were building websites from scratch until web frameworks like Ruby on Rails or Django emerged. And while today we have mature but low-level RDF frameworks, there still is a lack of end-user platforms.
With LinkedDataHub 2.0 custom applications can be prototyped very quickly and cost-effectively on top of RDF Knowledge Graphs thanks to the low-code nature of the platform, which is enabled by its data-driven architecture. For example, the configuration of facets and parallax is configured using a single SELECT query — no code is required. The KG can be accessed from any SPARQL-compliant datasource — either an existing one, or one that can be mapped and integrated from legacy systems.
LinkedDataHub is generic in the sense that it can be applied to any RDF dataset and it provides a functional default UI that can readily serve as a prototype application. Furthermore, the UI is completely customizable for any specific case, and the customization results in a much faster and cheaper development. In other words, you can arrive at the same result as writing custom code from scratch but at a fraction of the cost. The value proposition behind LinkedDataHub is a much quicker time to value for your Knowledge Graph.
Build your first knowledge graph app at LinkedDataHub 2.0. Get started.
In addition to the open-source edition, we are working on a managed cloud version of LinkedDataHub which will feature multiple dataspaces per user without any setup involved. They can be created with a click of a button, just like GitHub repositories. Drop us a line for an early access to the first Knowledge Graph-powered cloud application platform.