Data-driven Software Architecture
Part 2/3: Why organizations need to adopt the data-driven architecture and a common data model
July 9, 2020
In the first part of this series of posts on Data-driven Architecture we discussed the problems with the web architecture built on legacy systems and the limitations this creates for the future of software and its role in the enterprise. We also talked about the upcoming software apocalypse and promised to present you with simpler and smarter ways for handling enterprise data and application software.
Here we will explain the rationale behind a data-driven approach and the need for a common data model. You will also learn why RDF is the only web-native data model that can unleash the true potential of the data-driven approach, offering a solution for the API proliferation problem.
The data is permanent and enduring, and applications can come and go.
As the number of APIs and the size of codebases continues to grow, software is becoming a larger and increasingly important part of our digital society. However, experts warn that this exponential growth is driving us towards a “software apocalypse” — the trend of continuous growth in software complexity, in other words: more code leads to more complexity.
Fortunately, there is an alternative to this potential "software apocalypse" and it is the data-driven architecture (DDA).
The rationale behind the data-driven approach
Data-driven architecture puts data at the center and makes data drive software, instead of code driving the data. It also decouples applications from data.

MVC framework
For example, within the common Model-View-Controller application pattern that we discussed in the previous blog post, such decoupling can be done in two main ways:
- By decoupling business logic (models, taxonomies, rules, constraints etc.) from code and moving it to data. This mostly concerns the Model component
- By replacing the remaining imperative code in the Controller and the View with declarative technologies
Application software can be so completely stripped of application-specific logic that it becomes a generic platform, which can be instantiated as an application by feeding application-specific data to it. Application development becomes configuration more than coding.
This idea is not new. The latest incarnation is known as low code/no code platforms. Webflow enables users to build web interfaces without being frontend developers. Microsoft PowerApps lets users build domain-driven applications without coding. Unfortunately, these platforms are built with proprietary technologies.
Data decoupled from applications is a prerequisite for the decentralized architecture and data ownership as well:
Decentralizing the Web means that people gain the ability to store their data wherever they want, while still getting the services they need. This requires major changes in the way we develop applications, as we migrate from a closed back-end database to the open Web as our data source.
It has been said that software is eating the world. It's time for data to eat the software. The first step in that direction is making data interoperable.
The need for a common data model
Data is much easier to change and deliver than code: it can be validated, transformed (for example, to a user interface) and does not have to be compiled. As a result, application development becomes rapid, more accessible to end-users. At the same time, the cost of change, which is regarded by some as the most important software project metric, drops. The change could be as simple as adding a field to a form in UI, which then propagates down through the layers all the way to the database. A flexible, data-driven system might be simply configured with an additional field; a legacy, code-based one might incur hundreds of hours of expensive development.
However, the true potential of the data-driven approach is unleashed when it is combined with a common data model. Such a model has a flexible structure which can accommodate data from any domain. Interoperability and data interchange must be built into its design.
A Data-Centric enterprise is one where all application functionality is based on a single, simple, extensible data model.
RDF Knowledge Graphs at the core of the data-centric approach
Graphs and networks are a natural and flexible way to describe our world, both the physical one and the conceptual one (some even argue that the laws of physics can be expressed as graph transformations). Resource Description Framework (RDF) is the only standard graph data model with the only standard graph query language (SPARQL). As a result, RDF is increasingly used to store and publish graph data — an approach now known as Knowledge Graph.
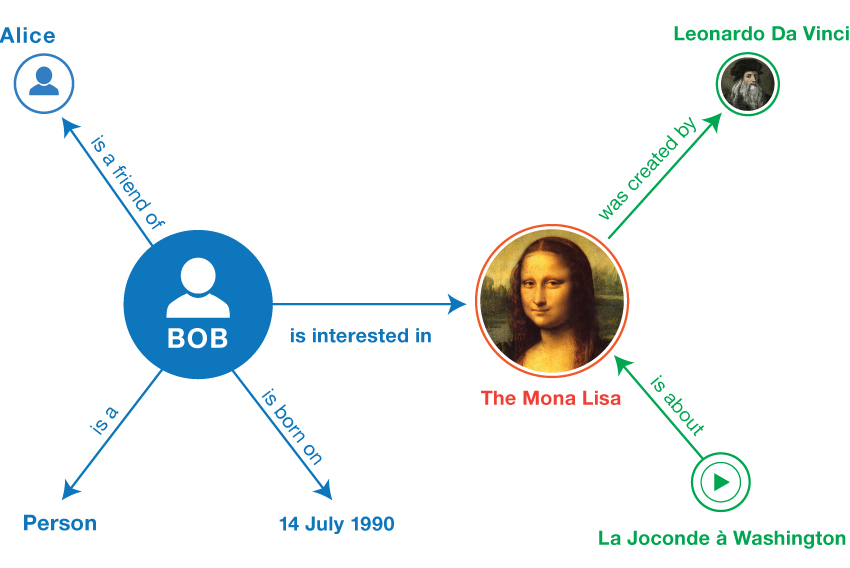
An RDF graph
Moreover, RDF is the only data model designed for the web. Internally, RDF uses the same identifiers as the web: URIs. URIs as built-in global identifiers and the zero-cost merge of RDF datasets are essential features for data publishing and interchange, from in-house to web-scale.
RDF also includes higher-level specifications (RDF Schema, Web Ontology Language) that allow ontology construction. Ontologies are formal definitions of domain models and they make these models reusable across applications as well as composable and queryable. They serve as a prime example of decoupling domain and business logic from source code.
Many developers complain about the steep learning curve of the RDF technologies. We feel it is best countered with a quote from Dan Brickley, one of the original authors of RDF:
People think RDF is a pain because it is complicated. The truth is even worse. RDF is painfully simplistic, but it allows you to work with real-world data and problems that are horribly complicated. While you can avoid RDF, it is harder to avoid complicated data and complicated computer problems. RDF brings together data across application boundaries and imposes no discipline on mandatory or expected structures.
RDF enables next-generation software
To take full advantage of RDF's features and ontologies, the application software has to be data-centric and tailored for RDF. Taking a legacy application-centric codebase and bolting RDF on as an afterthought, for example by replacing an RDBMS with a triplestore while keeping the other legacy components such as ORM, achieves nothing.
RDF offers a solution for the API proliferation problem as well. What is the opposite to tens of thousands of APIs and counting? One uniform read-write Linked Data API for all services. HTTP interactions can be mapped to simple CRUD operations on RDF statements, given that the system is RDF-based.
So far the software applications are only beginning to tap into the RDF's potential. Our goal is to exploit it to the fullest extent, so that the technology reaches a point where the end-users are not even aware they are using an RDF-powered application yet are provided with a rich user experience which is impossible to create otherwise.
In the next part of the series where you will learn how you can take a data-driven approach and tap into the potential of RDF by using LinkedDataHub, AtomGraph's Knowledge Graph Management System. Follow our updates on Twitter and LinkedIn and join the conversation.